

本文主要讲解 两个重点。
1,汇编代码 对应的 机器码是怎么样的
2,为什么用汇编实现某些功能会比 C语言 性能好。
C语言代码:
int add_two(int a,int b){
return a+b;
}
int main() {
int return_num = add_two(1,8);
return return_num - 3;
}汇编代码:
.text
.globl main
.type main, @function
.type add_two, @function
add_two:
movl %ebx, %eax
addl %ecx, %eax
ret
main:
pushl %ebp
movl %esp, %ebp
/* 两个参数 分别传进去 ebx ,ecx,所以需要先 保存 ebx ,ecx 的旧值进去 堆栈。 */
pushl %ebx
pushl %ecx
/* 开始寄存器传参, 参数 1 丢进去 ebx,参数 8 丢进去 ecx */
movl $1, %ebx
movl $8, %ecx
call add_two
/* 从堆栈恢复 ecx ebx的值 */
popl %ecx
popl %ebx
/* 返回值减 3 */
subl $3, %eax
popl %ebp
ret执行以下命令,编译,调试 汇编可执行文件。
gcc -m32 -o main-32 main-32.s
# 运行 gdb
gdb ./main-32
# 显示寄存器窗口
layout regs
# 断点
b *main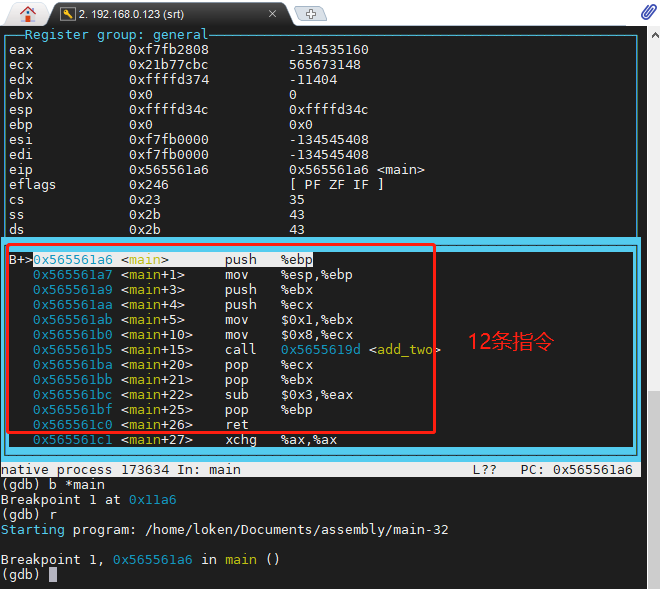
汇编代码,是一条 汇编 指令 就对应 一条机器指令,所以从上图看来,main 函数占 12条指令,add_two 函数占 3 条指令,加起来,CPU 运行 汇编程序 只需要 15条指令就可以了。
由于 eip 寄存器指向 0x565561a6 ,所以 mian 函数的 机器码就在 0x565561a6 ~ 0x565561c0 的位置,一共 0x1A 字节大小。
汇编 跟 机器码 表如下:
| 汇编代码 | 位置 | 占用字节数 | 机器码 (大端序) |
|---|---|---|---|
pushl %ebp | 0x565561a6 ~ 0x565561a7 | 1 | 0x55 |
addl %ecx, %eax | 0x565561a7 ~ 0x565561a9 | 2 | 0xe5 0x89 |
pushl %ebx | 0x565561a9 ~ 0x565561aa | 1 | 0x53 |
pushl %ecx | 0x565561aa ~ 0x565561ab | 1 | 0x51 |
movl $1, %ebx | 0x565561ab ~ 0x565561b0 | 5 | 0x00 0x00 0x00 0x01 0xbb |
movl $8, %ecx | 0x565561b0 ~ 0x565561b5 | 5 | 0x00 0x00 0x00 0x08 0xb9 |
call add_two | 0x565561b5 ~ 0x565561ba | 5 | 0xff 0xff 0xff 0xe3 0xe8 |
| 省略..... | 0x565561ba ~ 0x565561bf | 5 | |
popl %ebp | 0x565561bf ~ 0x565561c0 | 1 | 0x5d |
ret | 0x565561c0 ~ 0x565561c1 | 1 | 0xc3 |
| 一共 | 27 |
机器码原来是 小端序的,表格为了方便查看,改成大端序。
现在 再来看看 如果把 之前的 C语言代码 编译成 汇编代码,会有多少条指令。
int add_two(int a,int b){
return a+b;
}
int main() {
int return_num = add_two(1,8);
return return_num - 3;
}执行以下命令:
gcc -m32 -o main-32-c main-32.c
# 运行 gdb
gdb ./main-32-c
# 显示寄存器窗口
layout regs
# 断点
b *main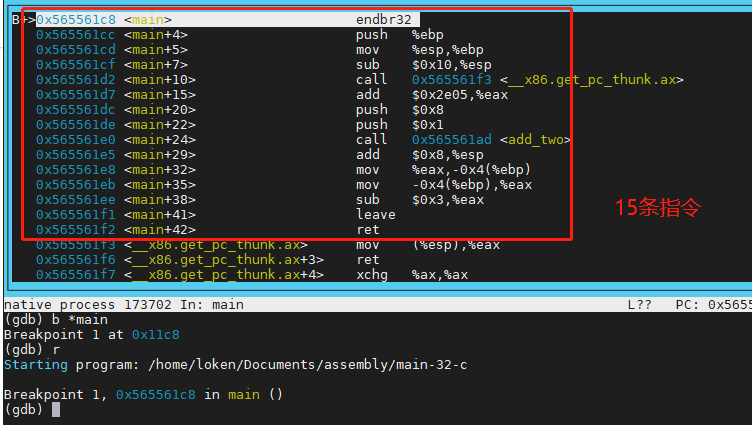
从上图可以看出,main 函数 15 条指令,add_two 函数 10 条指令,C语言代码 比 汇编代码多了 10条指令。这还只是 我们的C代码的指令条数,注意 C代码是运行在 /lib32/libc.so 运行时库里面的。所以上面的截图底部还有一些指令 get_pc_thunk.ax 要执行。
这个是因为C语言为了调试方便, 会 利用 GOT 表 等技术来操作汇编变量。
这是为了调试方便,开发效率而牺牲的性能。
扩展知识:
我们在用 notepad++ 来查看一下 之前汇编代码 生成的可执行文件是怎样的。
直接搜索(小端序),下面就是汇编代码对应的部分机器码
55 89 e5 53 51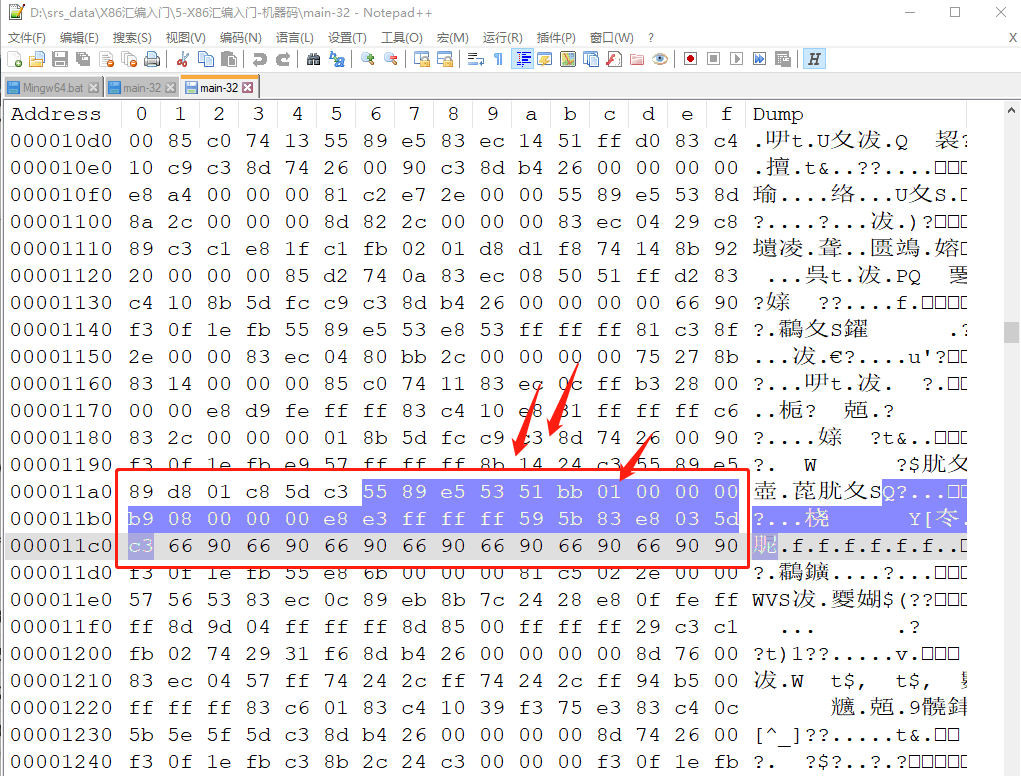
从上图可以看到,实际的机器码只有 27 字节,其他的应该都是操作系统 加的东西。
之前说过 汇编代码 大多数情况,也是运行在操作系统之上的。
由于笔者的水平有限, 加之编写的同时还要参与开发工作,文中难免会出现一些错误或者不准确的地方,恳请读者批评指正。如果读者有任何宝贵意见,可以加我微信 Loken1。QQ:2338195090。