

C++ 里面有一个非常独特的功能,叫 "右值引用",刚学 C++ 的人都会觉得这个东西非常反人类,我也一样的。
我个人认为,要理解 右值引用 这玩意,需要先学习汇编,如果没学 汇编,直接学 C++ 的右值引用就会觉得它反人类,不易理解。
C++ 里面的 左值,右值,对应的英文缩写是 lvalue 跟 rvalue,但是目前,市面上,这两种概念有不同的翻译。
例如有些人说 lvalue 的全称是 loactor value,可定位的值,这个实际上是指你在 C/C++ 代码里面能用标识符 定位到的值,例如 int a = 1,这里的 a 就是一个标识符,a 就是 loactor value。
而 rvalue 的全称是 read value,只可读取的值。我个人觉得这个翻译解释也不太对,并不是只读的值,而是 rvalue 是指一个临时变量,或者说是匿名变量,这个变量是没有标识符的。
所以我个人倾向于,rvalue 的正确翻译是 右值 (临时变量), lvalue 的正确翻译是 loactor value (可定位值),而不应该翻译成左值。
左值跟右值,不是说变量在左边他就是左值,在右边他就是右值,不是这个意思,不要被这个术语误导。例如下面的代码:
int&& b = 10;上面的 b 就是对右值的引用。但是他在左边。
上面这种代码写法是没有意义的,跟直接 int b=10 几乎一样,而且上面这样写 && 还会损失性能,多执行两条汇编,有兴趣可以自行反汇编。
我个人特别不喜欢用 int&& b = 10; 来讲解右值,因为现实工程代码根本不会这样写,能这么写代码,只是恰好编译器能让你这么写。但是这样写代码又有什么意义,我喜欢举实际有用的例子来讲解右值。
讲到这里,可能读者会有疑问,所有变量都应该有标识符的,没有标识符怎么能叫做变量呢?
我通过一个简单的代码,演示一下,大家就明白了。
代码如下:
#include <iostream>
int main() {
int a = 2;
int b = a * 5;
return 0;
}上面的代码,翻译成汇编,如下:
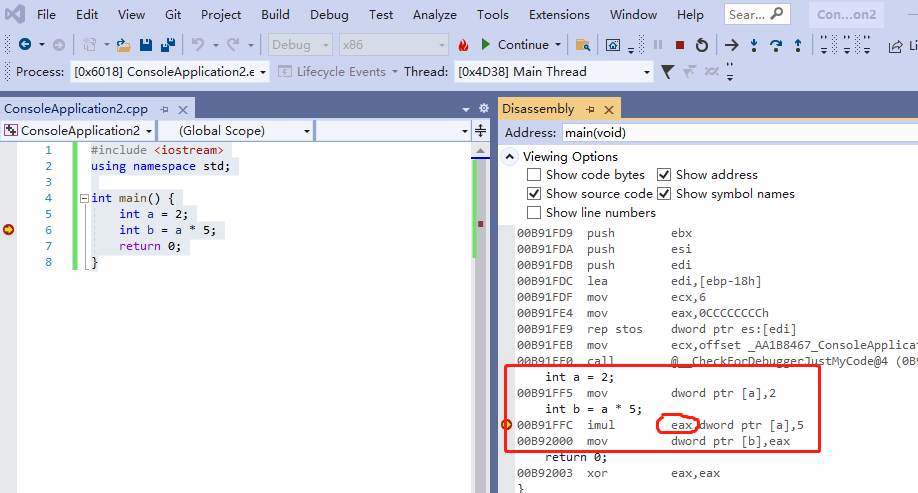
我上图圈出来的 eax ,他就是右值。
为什么会产生右值,是因为 汇编,CPU 指令无法 直接把结果直接存进去另一块内存,结果需要存在 eax 里面,然后再复制到另一块内存。变量都是放在内存里面的。
x86 指令的内存寻址比较强大,所以产生的右值比较少,而 ARM 指令没那么强大,会产生更多的右值。
CPU 指令,需要一个缓存,一个中间的处理。因此就诞生了右值这个概念,右值这个概念,他不是 C++ 独有的,而是在 C 语言里面编程就会遇到 右值的。
为什么说 右值 是一个临时值,是因为 eax 寄存器就是一个临时值。
上面的 a * 5 执行完之后,右值 eax 是 10。我再加一些代码在后面,如下:
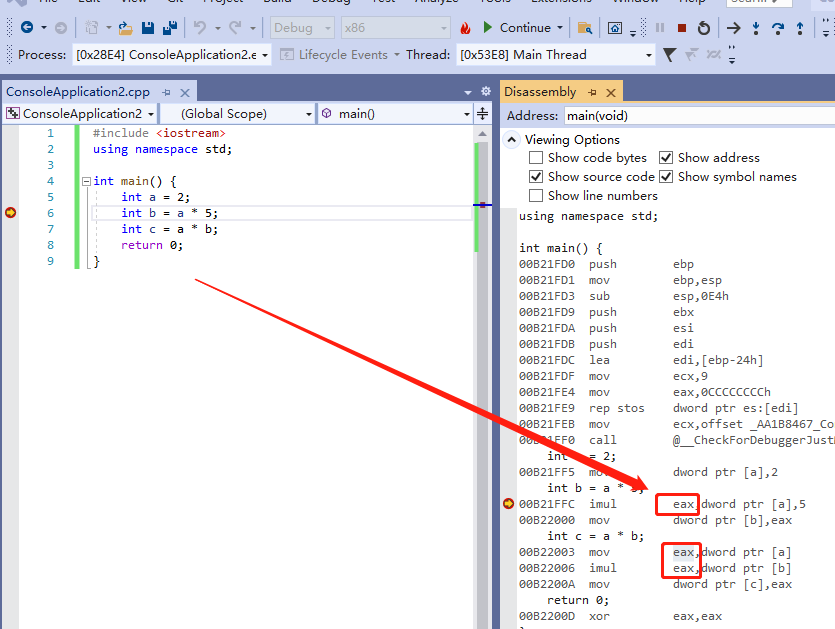
可以看到,后面的代码,会覆盖 eax 的值。只要后面的代码执行,你就无法找到那个曾经 等于 10 的右值变量。而 a ,b 这些是 左值变量,也叫 可定位变量,无论代码怎么跑,你都能通过 a 这个标识符,找到那个等于 2 的变量。
做个小总结,右值是临时的,而 左值是永久的。
下面我们来讲一个 函数调用,值拷贝的例子,代码如下:
#include <iostream>
using namespace std;
struct Box {
int length; // 盒子的长度
int breadth; // 盒子的宽度
int height;
};
struct Box getBox() {
struct Box b1;
b1.length = 1;
b1.breadth = 2;
b1.height = 3;
return b1;
}
int main() {
struct Box my_box = getBox();
return 0;
}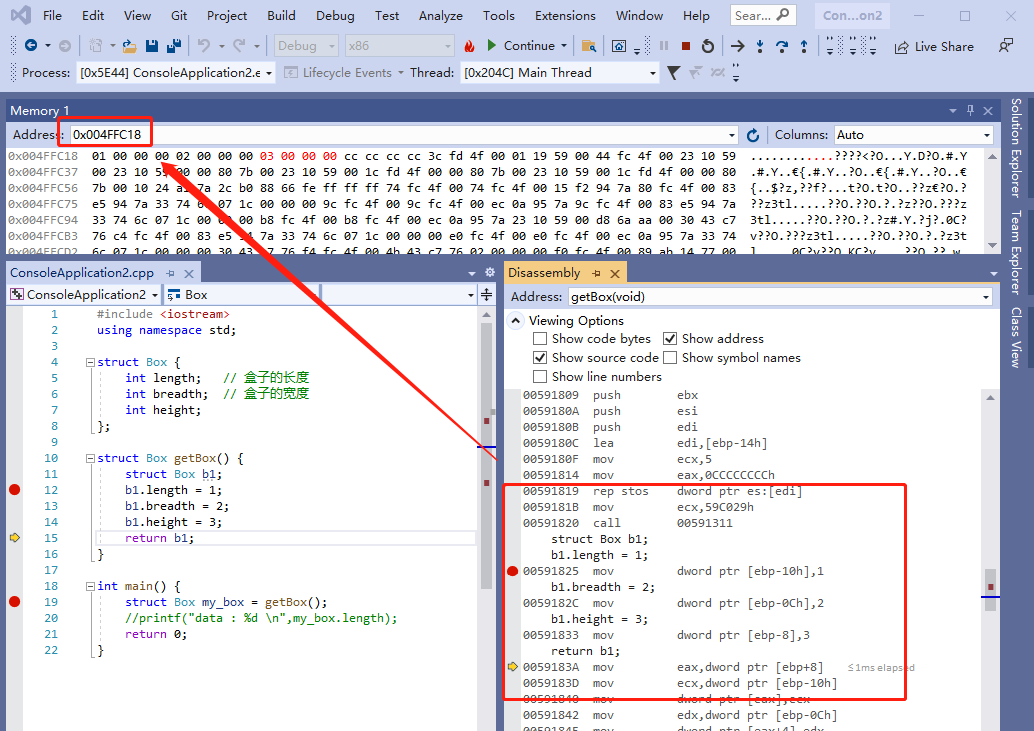
从上图可以看出, 局部变量 b1 的内存起始地址是 ebp-10h ,也就是 0x00FAFAE0,一直到 ebp-8h,也就是 b1 变量的数据在 0x00FAFAE0 ~ 0x00FAFAEC。
由于 b1 是局部变量,所以它的内存是在 栈上面的,0x00FAFAE0 是属于栈内存的地址,当函数返回的时候,ebp 寄存器就会恢复。后面的代码极有可能会再次压栈,所以函数返回之后 0x004FFC18 地址的内存数据后面极有可能会被修改。
这就是 局部变量为什么在函数返回之后,就有可能失效的原因。所以变量都是在内存里面的,只是有些变量在栈里,有些在堆里面。堆变量不会被隐性修改,所以需要手动释放内存。而栈变量的内存会随着各个函数调用被修改,不需要你手动释放内存。
而我们上面的代码,return 返回的不是 b1 的指针,而是 b1 的值。所以 b1 的值会被拷贝到一个临时的存储空间,这个临时的存储空间就是右值,如下:
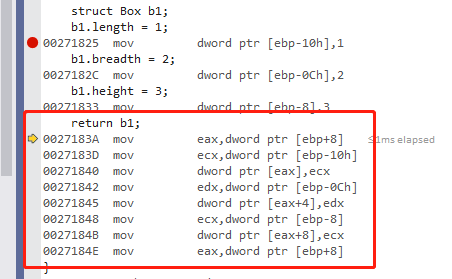
可以看到,return b1 被翻译成 8 句汇编代码。现在来仔细讲解一下 这 8 句汇编在干什么。
1,mov eax,dword ptr [ebp+8]
我们知道,函数内部创建局域变量的时候, ebp 是减的,也就是变得越来越小。而 ebp + 8 代表什么意思?往上加,代表跳回到上层调用者的栈内存里面。
所以现在 eax 存的是调用者的栈地址。
补充:也可能不是调回到 上层调用者的栈内存,而是函数本身会保留一块内存来放返回值。
后面的 7 句汇编,实际上就是把 内部的局部变量,全部拷贝到 调用者的栈里面,这样,调用者就能拿到这个返回值。下面我们来看一下调用者是如何拿这个返回值的,如下:
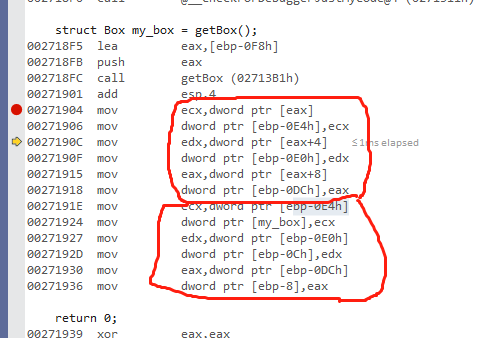
从上图可以看到,从 getBox 返回之后,还会进行一次拷贝,首先 eax 存储的就是 返回值的起始地址。
我们总结一下整个 拷贝过程。
1,return b1 ,需要把 b1 的值 复制到 内存 A。
2,从 b1 返回之后,eax 就会指向 内存 A,然后把 内存 A 复制到 匿名变量内存B。
3,把匿名变量 赋值到 my_box。
流程如图:
局部变量 b1 -> 内存A -> 匿名内存B -> 变量 my_box。
值传递,经历了 3 次 内存拷贝。
现在我用一些 hack 的方法来优化一下上面的代码,如下:
struct Box {
int length; // 盒子的长度
int breadth; // 盒子的宽度
int height;
};
struct Box* getBox() {
struct Box b1;
b1.length = 1;
b1.breadth = 2;
b1.height = 3;
return &b1;
}
int main() {
struct Box my_box;
my_box = *(getBox());
return 0;
}我直接返回局部变量的内存指针,这是一种不正规的做法,但是因为这个指针的内存返回之后就被立即取值了,所以获取到的是正确的数据。如下:

可以看到,getBox() 函数的汇编代码少了几行。在看一下 main 函数的汇编,如下:
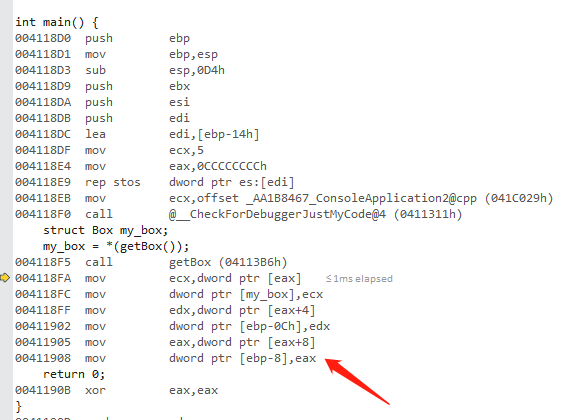
可以看到,只进行了一次内存拷贝。直接把局部变量的内存拷贝到上层调用者的 my_box 里面,因为 getBox 函数调用之后,就立即取他的内存,所以他的内存还没有损坏。可以看到 my_box 的值如下,正常被赋值为 1,2,3。
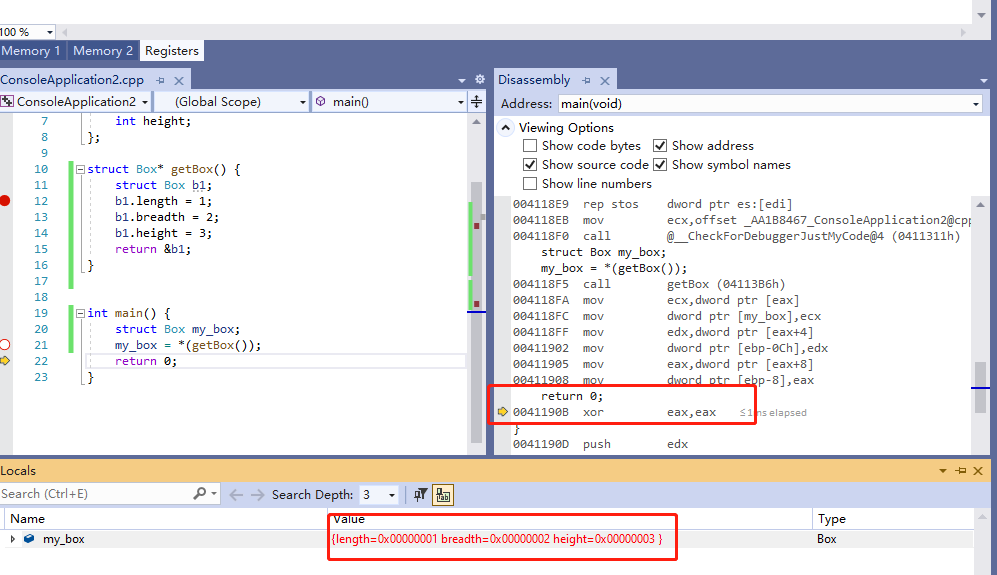
这种 hack 的做法,减少了 两次 内存拷贝,大大提升了性能,但毕竟这不是一种正规的写法,稍不注意就会导致问题。
因为局部变量的内存也是内存,都是我们可以控制的,既然知道了数据在哪里,直接 copy 一次给变量不就行了。由此可见,值传递是比较消耗性能的。
而右值引用,也是为了减少内存拷贝,下面就来演示一下 C++ 里面的右值引用是如何减少内存拷贝的。
先来个简单的例子,如下:
int getNum() {
int num = 5;
return num;
}
int main() {
int&& my_box = getNum();
return 0;
}反汇编后如下;
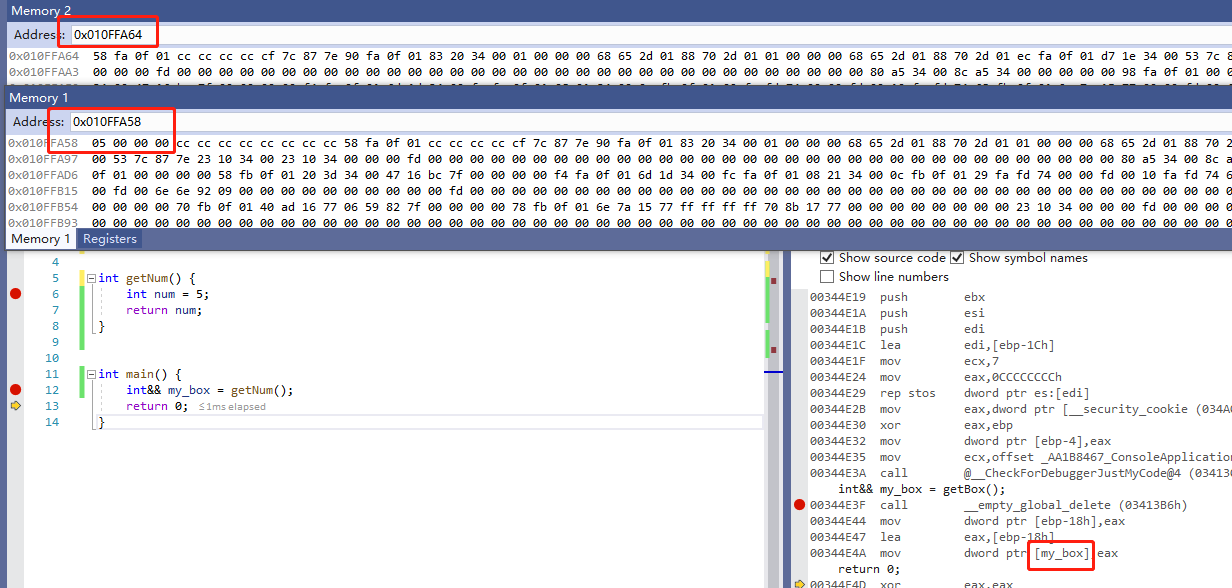
上图中,my_box 是 0x010FFA64,并没有减少什么内存拷贝,反而比 不用 && 多了两句汇编,在上面的代码中,my_box 类似于一级指针,他指向的内存才是 5 。my_box 本身不是 5,这就是那两句汇编干的活。
把 eax 的值复制到 ebp-18h ,让右值的生命周期延长。然后把 my_box 指向 ebp-18h ,这样 my_box 就类似一级指针了。
由此可将,上面这样使用右值引用 并没有什么卵用,还会多执行两句汇编。
下面就来讲一个 右值引用真正发挥他的作用的场景,如下:
待写.....
由于笔者的水平有限,文中难免会出现一些错误或者不准确的地方,恳请读者批评指正。如果读者有任何宝贵意见,可以加我微信 Loken1。
博主,你这个博客系统是用的什么方式搭建的?
@haige wordpress + Adams 主题