

作者:罗上文,微信:Loken1,公众号:FFmpeg弦外之音
本文使用的命令如下:
ffmpeg -i juren-30s.h264 out.flv -y
请参考《用Ubuntu18与clion调试FFmpeg》搭建好调试环境,juren-30s.h264 在 GitHub 里面有的,请自行下载。
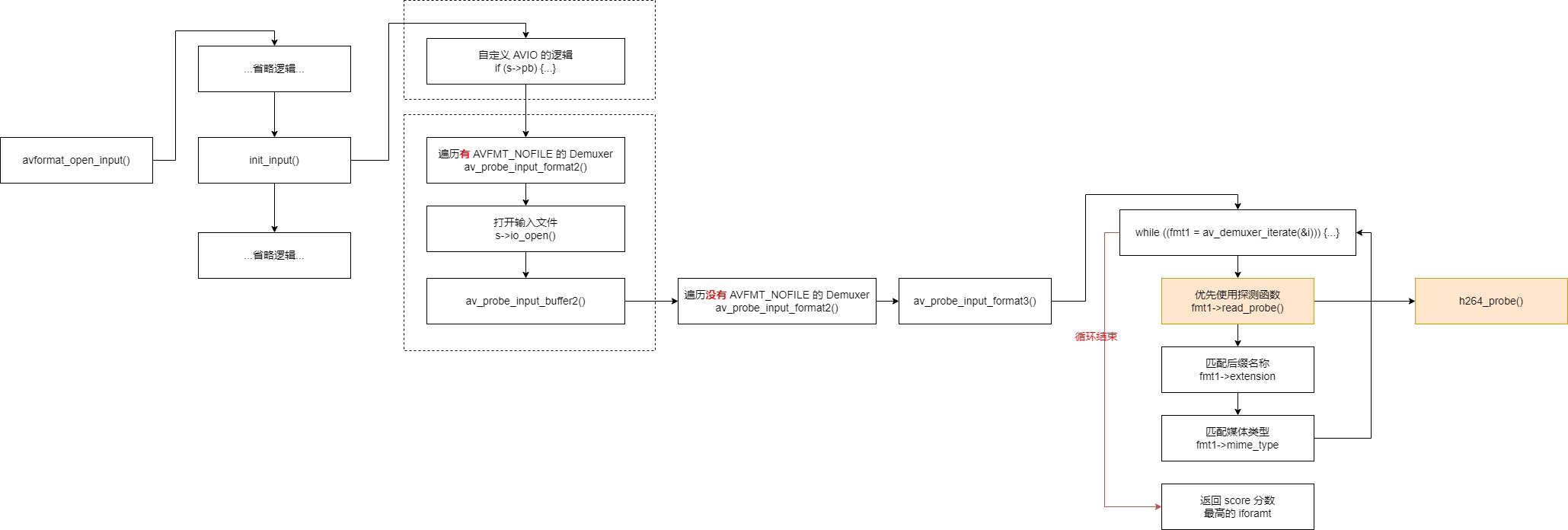
几乎每一个 Demuxer 都有自己的 probe 探测函数的,探测函数被调用的位置,如下:
h264_probe() 函数的内部流程如下:
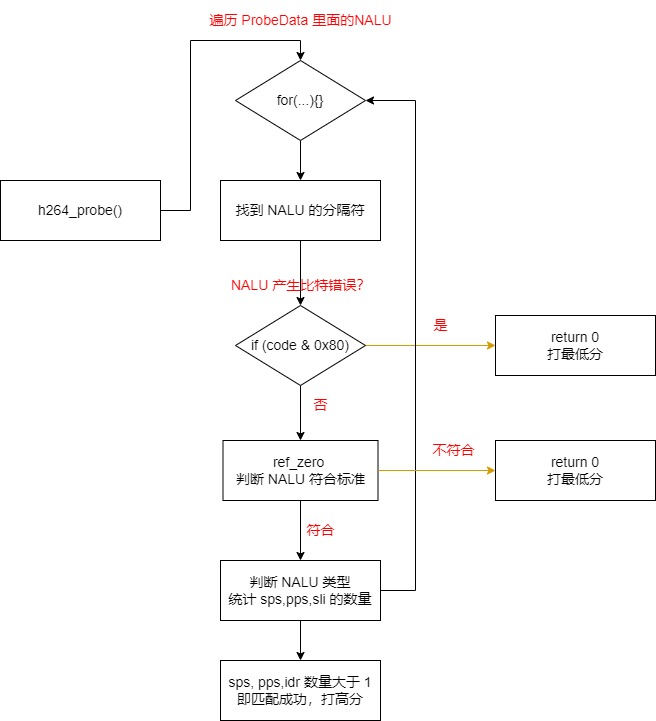
h264_probe() 函数的重点如下:
1,找到每个 NALU 的开头
Annex B 格式的各个 NALU 之间是用 Start Codes (0x000001) 跟 填充字符 0 来分隔。所以在 for 循环里面,需要找到 起始码,同时还要处理填充字符 0,如下:
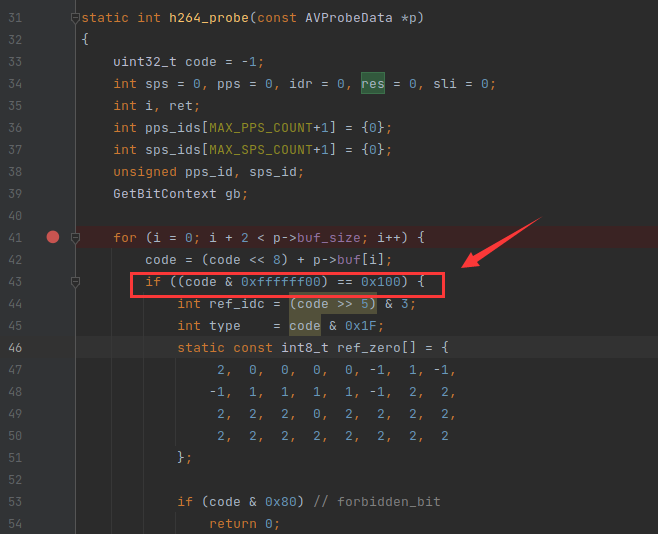
这段代码是比较复杂的,我也看了挺久的,首先变量 code 默认是 -1,注意,他是无符号的 32位类型的。所以 code 的二进制表示是
code = -1 = 0b1111 1111 1111 1111 1111 1111 1111 1111
code 内存的 32 位全部都是 1,然后他循环里,每次都把 code 右移 8 位,运算如下:
0b1111 1111 1111 1111 1111 1111 1111 1111 << 8 = 0b1111 1111 1111 1111 1111 1111 0000 0000
可以看到,最后8位变成了 0,所以空出来了8位的空间。这 8 位的内存空间,其实是给 p->buf[i] 用的,p->buf[i] 占 8 位。
所以 (code << 8) + p->buf[i] 这句代码的含义,就是每次都读取一个字节,然后放在末尾。
然后,下面的这句代码也是不太容易理解的,如下:
if ((code & 0xffffff00) == 0x100)
因为 起始码 前面可能会填充多个 0 来对齐数据长度,所以我们需要处理填充字符。其实这段代码是处理了填充字符 0 的。你需要把 0xffffff00 跟 0x100 转成二进制才能看懂他的代码。
0xffffff00 = 0b1111 1111 1111 1111 1111 1111 0000 0000
0x100 = 0b0000 0000 0000 0000 0000 0001 0000 0000
因此 code & 0xffffff00 操作,会消除最后 8 位,但是,但是,前面的 24 位是保留的,所以上一次读取出来的那个字节是保留下来的,注意,是上一次。
因此当读取到 67 这个字节的时候,如下,67 就会被放到变量 code 的后 8 位,这时候 code 就等于下面的值。
code = 0b0000 0000 0000 0000 0000 0001 0110 0111

因此 if ((code & 0xffffff00) == 0x100) 就会成立,就算找到 NALU 了。读者可以自行调试一下,就很容易看懂这段代码。
小总结:这段代码的逻辑其实就是要找到一字节的 0x1,然后前面的 2 个字节必须全是 0 ,这就是找到 NALU 的逻辑。
2,判断 NALU 是否产生了比特错误
之前在《H.264 Annex B格式分析》讲过,NALU 头部的第一位如果是 1,也就是 forbidden_bit 字段如果等于 1,就代表这个 NALU 发生了比特错误,所以下面这句代码就是判断 比特错误的。
if (code & 0x80) // forbidden_bit
return 0;
0x80 转成 二进制表达如下:
0x80 = 0b1000 0000
3,ref_zero 判断 NALU 是否符合H.264标准
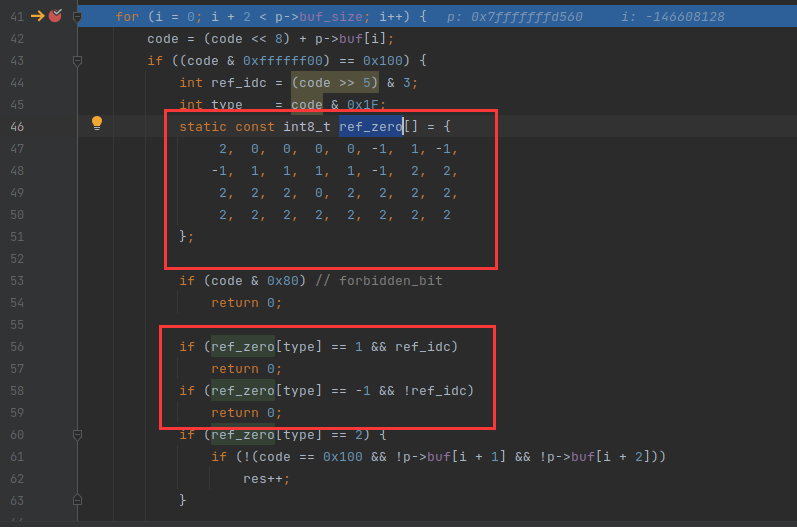
上图中的 变量 ref_idc 就是 StreamAnalyzer 软件里面展示的 nal_ref_idc ,变量 type 就是 nal_unit_type,如下:
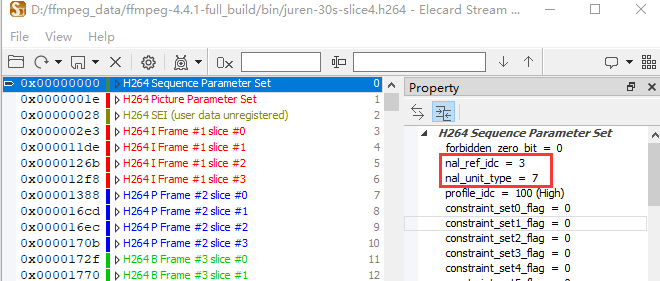
那 ref_zero[] 这个变量是干什么的呢?我也不知道他为什么起名字叫 zero,但是这个命名还是挺好的。只是我不知道怎么把 zero 翻译成中文表达给大家听。
ref_zero[] 其实是一个映射表,这个映射表是用来判断 NALU 的数据是否符合H264标准。这个在《新一代视频压缩编码标准》一书有介绍,如下:
al_ref_idc指的是当前 NAL 的优先级。取值范围为 0~3,值越高,表示当前 NAL 越重要,越需要优先受到保护。H.264 规定如果当前 NAL 是一个序列参数集,或一个图像参数集,属于参考图像的片或片分区等重要的数据单位时,本句法元素必须大于0。但在大于 0 时具体该取何值,并没有进一步的规定,通信双方可以灵活地制定策略。当nal_unit_type等于 5 时,nal_ref_idc大于 0。当nal_unit_type等于 6、9、10、11 或12 时,nal_ref_idc等于 0。
上面这段话,其实也是 H.264 标准的内容,他限制了在什么场景下,nal_ref_idc 的取值范围,必须这么做。
我们基于这个逻辑来理解 FFmpeg 的代码就好理解很多了,例如下面这句代码。
if (ref_zero[type] == 1 && ref_idc)
return 0;
ref_zero[] 数组里,哪些 type 等于 1 ?就是 6、9、10、11 或12。在这些场景下,如果 ref_idc 不等于 0,也就是有值,这个 NALU 就不符合标准,就直接返回 0,0 是最低的打分。
其他的判断也是类似的原理,读者自行推导一番就可以了。
4,统计 sps,pps 等 NALU 的数量
当通过 zero_ref 的判断之后,就代表这个 NALU 是符合 H.264 标准的。然后根据 type 来判断 NALU 的类型,来统计 NALU。

最后,如果找到 sps,pps 等 NALU 数据,h264_probe() 函数返回的分数就会很高,就可以探测出来输入的数据是 h.264 了。
h264_probe() 函数里面还有一些代码是没有讲解的,请读者自行思考,如下:
1,变量 res 代表什么?
if (ref_zero[type] == 2) {
if (!(code == 0x100 && !p->buf[i + 1] && !p->buf[i + 2]))
res++;
}2,函数 init_get_bits8() 有何作用?
ret = init_get_bits8(&gb, p->buf + i + 1, p->buf_size - i - 1);